
AI e Allucinazioni
Siamo presenti alla mostra “Sciamani, comunicare oltre l’invisibile”, una collaborazione tra MUSE e Mart, con un video realizzato da Andres Reyes, il nostro AI Designer, e prodotto da Brand & Soda.
Guarda il trailer della mostra
In una sala avvolgente nelle viscere di Palazzo delle Albere, al suono martellante di percussioni inesorabili, il visitatore è invitato - ma forse il termine giusto è sedotto - a sperimentare uno stato di alterazione della coscienza.
Come? Attraverso una camminata in un bosco del Trentino, filmata e poi opportunamente modificata. Lo sciamano, l’avrete capito, è chi guarda.
Lo spunto iniziale arriva dal lavoro del professor Nicola De Pisapia dell’Università di Trento, mentre le riprese video sono di Marco Soave e il montaggio audio e video è di Samuele Zuech.
Contenuti come questo sono resi possibili da intelligenze artificiali, messe in riga con un addestramento paziente e specifico. Andres ha utilizzato delle reti neurali convoluzionali (CNN) con un diagramma a blocchi.
Il percorso logico è il seguente: innanzitutto la rete prende in pasto un’immagine. In seguito entra in azione un “feature extractor” composto da un numero variabile di “filtri convoluzionali”, ossia degli elementi che estraggono varie proprietà dell'immagine come i bordi, i contorni, le texture.
Un classificatore le converte in categorie, come ad esempio “aletta di pollo”. Lacategoria che ha la probabilità più elevata di essere quella corretta viene identificata come prevista dall’algoritmo.
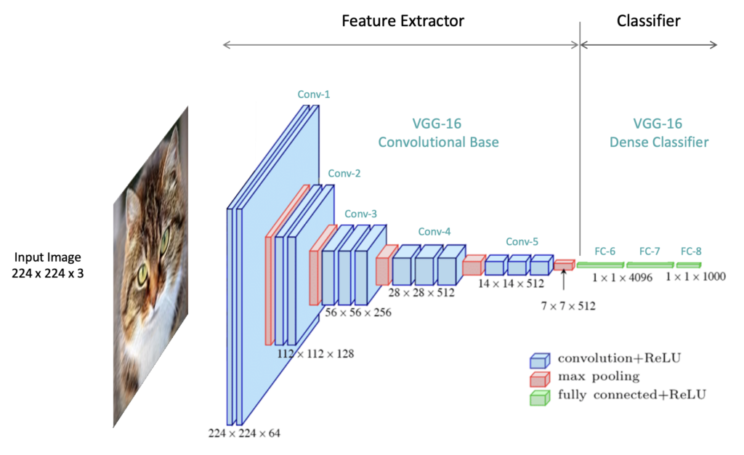
Come funziona il feature extractor
Guarda un estratto del ideo
Il concetto chiave
Inceptionism: continuare a modificare un contenuto di partenza per aumentare in modo grottesco quello che le reti neurali vedono.
Esiste quindi una fase di addestramento, durante la quale la rete neurale fa delle previsioni e poi verifica quanto sono accurate rispetto a quella che era stata definita “risposta corretta”. L’operatore ha a disposizione uno strumento, in questo processo di tira e molla: il gradiente.
Va pensato come una bussola che indica alla rete neurale in quale direzione deve andare per migliorare la sua prestazione. Minimizzare il gradiente riduce l'errore di previsione dell'errore, e naturalmente è questo che di solito si fa, perché gli errori rompono le scatole.
Ora, la domanda da porsi è la seguente: cosa accade se prendiamo un’immagine, scegliamo un filtro convoluzionale e invece massimizziano il suo gradiente? Ovviamente Andres ci ha provato, tra un’aletta di pollo e l’altra, e poi ha controllato il risultato nei livelli del feature extractor.
Spingendo il gradiente al massimo si cerca di modificare l'immagine in modo che la rete neurale "veda" di più le features su cui è stata addestrata. Per esempio, se è stata addestrata a riconoscere alette di pollo, l'algoritmo modificherà l'immagine in modo che ci siano alette di pollo ovunque.
Questo processo si può fare, rifare, e rifare ancora. Ogni iterazione modifica l'immagine originale aumentando le features che lo strato della rete neurale sta cercando. Un diario delle prove qui è necessario, un po’ come quello del Dr. Jekyll.
Anche questo lavoro, che ci crediate o no, ha un nome: network feature visualization.
Fa schifo? Certo, e infatti ne ha un altro: “Inceptionism”. Ma su questo, vi invitiamo a studiare utilizzando le risorse di Google Research.
AI per il patrimonio culturale?
Scrivici a hello@machineria.it
